Claude Code + Ollama: Testando Opus 4.5 vs GLM 4.7
English version available at Codeminer42 Blog.
Ollama acabou de tornar possível usar seus modelos dentro do Claude Code.

Para testar as capacidades do Claude Code e comparar modelos open source com os fechados, comparei GLM 4.7 e Opus 4.5 em uma tarefa que exige atenção aos detalhes e habilidades de debugging.
O resumo é que Opus 4.5 superou GLM 4.7 por uma margem (que eu considero) grande. Isso faz o GLM 4.7 parecer inútil, mas não é.
Como Ollama Tornou Isso Possível
A tarefa de fazer isso funcionar é mais tediosa do que difícil.
Claude Code, como agente, apenas faz chamadas para os servidores da Anthropic para obter respostas do modelo. Fazer isso funcionar com qualquer outra API é questão de implementar um proxy que traduz as chamadas do Claude Code para a API de destino.
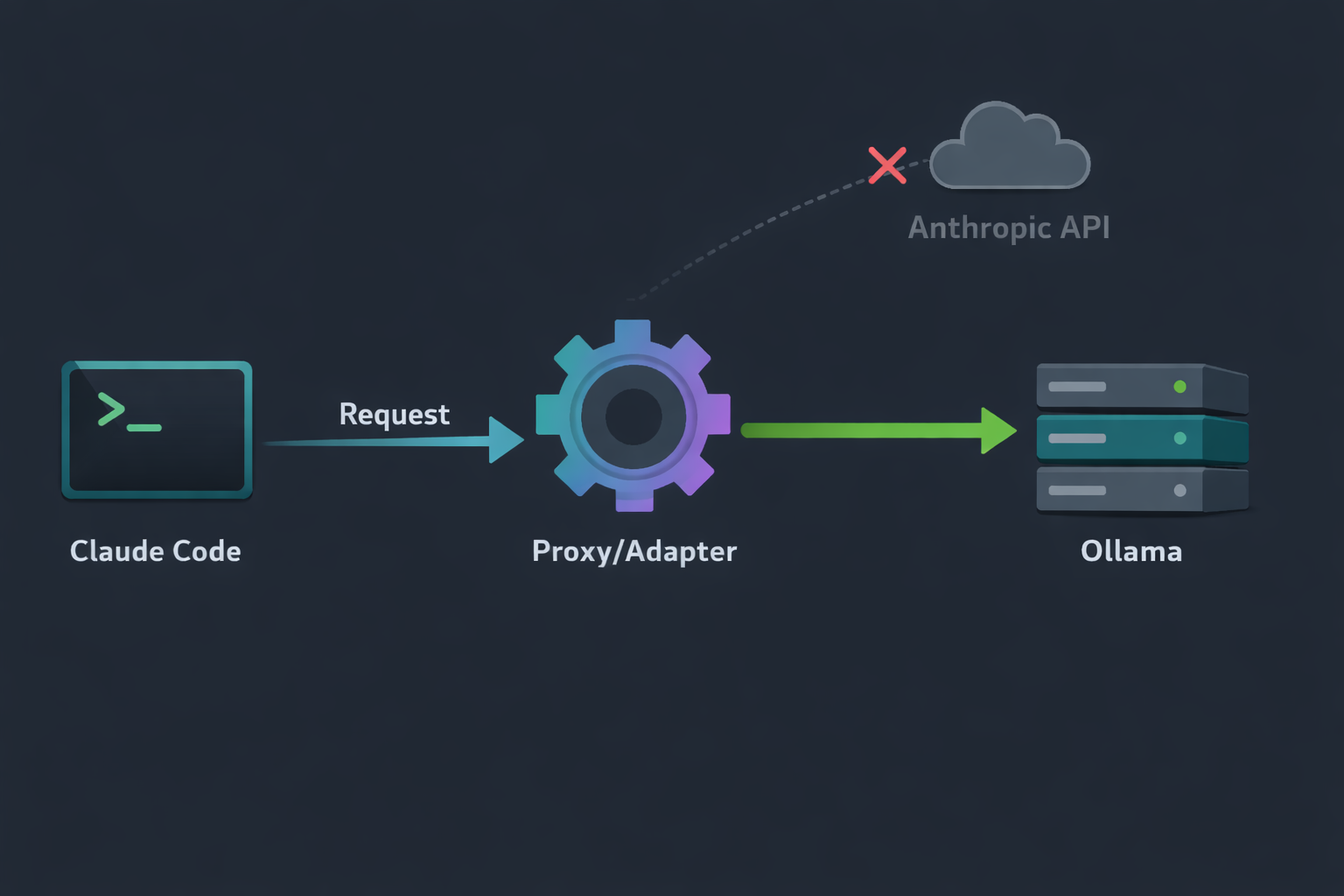
Não estou dizendo que esse trabalho não tem valor. Pelo contrário, é um ótimo trabalho que requer atenção e conhecimento de ambos os sistemas. Mas não é algo que só a Ollama poderia fazer. O claude-code-proxy fez a mesma coisa.
O Experimento
Venho usando OpenCode e Claude Code há um tempo. Curto a flexibilidade do OpenCode e eles têm uma TUI bem ergonômica. Melhor que a do Claude Code, pra ser honesto.
Mas o Claude Code sempre me deixou curioso. Sei que Opus é um modelo excelente, todo mundo que já usou pra tarefas de código concorda com isso.
Mas eu tinha essa ideia de que o Claude Code tem parte nessa grandeza. Agora que Ollama tornou isso possível, é uma boa chance de testar o Agente isolado do modelo.
Então decidi comparar Opus 4.5 vs GLM 4.7 dentro do Claude Code.
Configurando Claude Code com Ollama
Com a versão mais recente do Ollama é bem simples configurar o Claude Code para usar modelos Ollama. Você precisa definir duas variáveis de ambiente: ANTHROPIC_BASE_URL e ANTHROPIC_AUTH_TOKEN.
A primeira deve apontar para seu servidor Ollama local, geralmente http://localhost:11434/v1. A segunda pode ser qualquer coisa, na verdade.
O passo a passo é:
- Instalar Ollama
- Iniciar o servidor Ollama com
ollama serve - Baixar o modelo que você quer usar, ex:
ollama pull glm-4.7:cloud - Iniciar Claude Code com as variáveis de ambiente definidas:
ANTHROPIC_BASE_URL=http://localhost:11434 ANTHROPIC_AUTH_TOKEN=ollama claude --model glm-4.7:cloud
Estou usando GLM 4.7 da nuvem porque não tenho hardware suficiente pra rodar localmente. Se você tem uma GPU potente, pode rodar o modelo GLM 4.7 Flash localmente.
A Tarefa
Existe um equívoco comum. Como as pessoas tendem a usar Claude Code + modelos Claude, elas pensam que são a mesma coisa. Bom, não são. Claude Code é apenas um frontend que faz chamadas para uma API que realiza a inferência de IA.
Isso significa que podemos ter qualquer API de backend com qualquer modelo. É questão de trocar o backend mantendo compatibilidade com o frontend.
Com isso em mente, decidi que queria ver o Claude Code sendo alimentado pelo Gemini 3. Mas claro, estamos em 2026, eu não queria escrever código.
Decidi que essa seria a tarefa perfeita para testar ambos os modelos:
Ollama just implemented an adapter for Claude Code
https://github.com/ollama/ollama/blob/main/anthropic/anthropic.go
It acts as a proxy, requests are sent to Ollama API instead of anthropic server.
I want you to implement a proxy like this to Vertex API, but it should be in Node.js.
Make direct calls as in the following curl. Don't install any library for calling Vertex api.
curl "https://aiplatform.googleapis.com/v1/publishers/google/models/gemini-3-pro-preview:streamGenerateContent?key=YOUR_API_KEY" \
-X POST \
-H "Content-Type: application/json" \
-d '{
"contents": [
{
"role": "user",
"parts": [
{
"text": "Explain how AI works in a few words"
}
]
}
]
}'
I will provide the API key through CLI. It should get a server running. Claude Code will be pointed to it.
É um prompt simples. Dou a referência para a implementação do Ollama, o curl para chamar a API Vertex e só quero um servidor Node.js que funcione como proxy.
Um bom resultado deveria me dar um servidor proxy funcional que conseguisse se comunicar com o Claude Code. Não precisa ser perfeito, mas deveria funcionar.
Resultados
De erros de sintaxe a implementações erradas, ambos os modelos chegaram a uma solução funcional. Um deles, porém, foi bem mais eficiente.
Vamos ver a linha do tempo de ambas as tentativas começando com GLM 4.7.
GLM 4.7
Dei o prompt e um minuto depois recebi uma implementação. Coloquei o servidor pra rodar, sem erros de programação, mas o Claude Code não conseguiu obter resposta do servidor. Mandei um “hello” e não obtive resposta.
O próximo passo do agente foi debugar. Adicionou console logs (como todo bom desenvolvedor Node.js faz) e testei novamente.
As coisas estavam melhorando, uma resposta estava voltando pro Claude Code, mas era um erro da API Vertex.
❯ API Error: 400 {"error":{"type":"api_error","message":"Vertex AI returned 400: [{\n \"error\": {\n \"code\": 400,\n \"message\": \"Invalid JSON payload received. Unknown name \\\"text\\\" at 'system_instruction.parts[0]': Proto field is not repeating, cannot start list.\\nInvalid JSON payload received. Unknown name \\\"$schema\\\" at 'tools[0].function_declarations[0].parameters': Cannot find field.\\nInvalid JSON payload received. Unknown name \\\"exclusiveMinimum\\\" at
O problema foi encontrado, era devido a uma incompatibilidade entre o JSON enviado para Anthropic e o esperado pela API Vertex.
⏺ I see the issues. Vertex AI has two main problems:
1. System instruction format - The parts field structure is different for system instructions
2. Tool schema conversion - Anthropic uses full JSON Schema (with $schema, exclusiveMinimum, propertyNames) but Vertex AI only supports a subset
Ele disse que estava corrigido, tentei de novo e recebi outro erro 400. Eu queria ajudar mas era difícil entender os logs. Tinha informação demais. Estava printando um payload JSON inteiro que era muito longo.
O modelo então “melhorou” truncando os logs. Ajudou. Consegui ver que o proxy estava fazendo chamadas usando um nome de modelo errado. Deveria estar usando o nome do modelo que vem da requisição, não um hardcoded.
⏺ Done. The logging is now much cleaner:
- Truncates long strings (>200 chars) and large objects (>500 chars)
- Hides tool parameters and schema (just shows tool names)
- Simplified request logging (just shows method/path)
- Removed verbose debug logs for headers, body content, and Vertex candidates
O erro persistiu nas próximas duas tentativas. Estava fazendo algum replace em cima do modelo que vinha na requisição. Não faço ideia do porquê.
Então sugeri que ele simplesmente usasse o modelo da requisição.
❯ theres no need to replace anything
just do this
const model = anthropicReq.model;
Claude Code usa múltiplos modelos
Claude Code faz múltiplas chamadas para modelos quando você interage com ele e é esperto o suficiente para rotear requisições para diferentes modelos quando necessário.
Como nos meus testes eu estava enviando um simples prompt “hello”, ele estava usando um modelo menor para isso. Isso é ótimo, não há necessidade de usar um modelo grande e caro para tarefas simples.
De volta ao GLM
Quebrou de novo. O proxy estava enviando requisições para Vertex com o modelo chamado claude-haiku-4-5-20251001.
Solicitei um mapeamento de modelos Claude para modelos Vertex. O apontamento continuou e olhando os logs eu tinha certeza que estava tudo certo com a comunicação com Vertex.
Infelizmente, o modelo não conseguiu descobrir por que eu não estava recebendo resposta dentro do Claude Code.
Como última chance pro GLM, pedi pra ele verificar a implementação que o Opus tinha feito e ver se havia algo diferente.
Ele então corrigiu os problemas. Ainda recebi um erro relacionado à incompatibilidade do JSON schema enviado pro Vertex. O modelo então comentou isso e enviou um payload mínimo pro Vertex.
Consegui obter uma resposta do Vertex dentro do Claude Code mas não era o que eu esperava. Era como se eu estivesse falando diretamente com o Gemini.
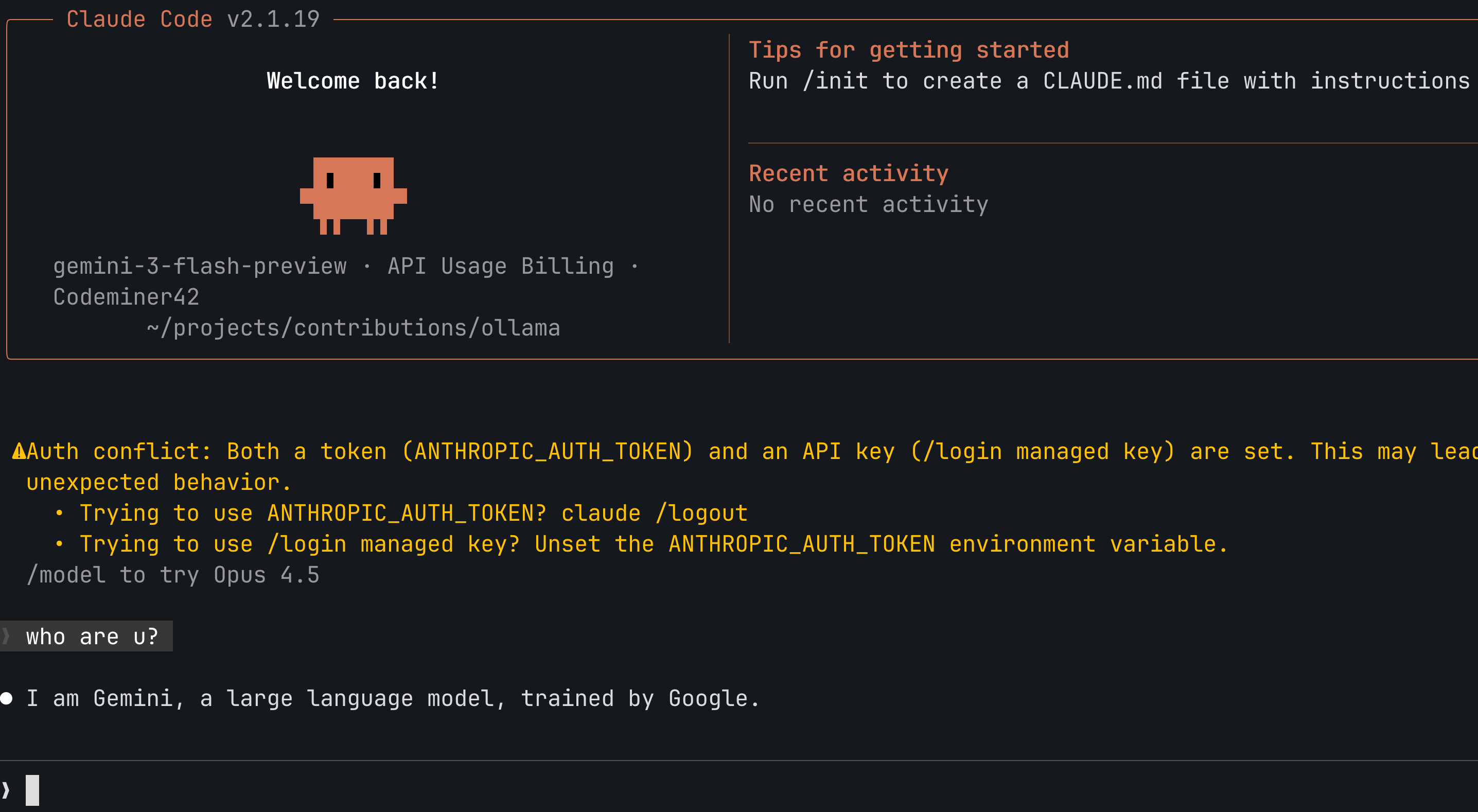
Não estava incorporando as instruções de sistema do Claude Code. Era apenas um proxy pro Gemini.
Claude Opus 4.5
Você viu no primeiro experimento que Opus conseguiu implementar um proxy funcional. O código produzido foi de fato usado como referência pro GLM corrigir sua implementação.
Dei o prompt pro Opus e um minuto depois tinha uma primeira implementação. Também com alguns problemas como:
- modelo não sendo obtido da requisição;
- nenhuma resposta chegando no Claude Code;
- endpoint errado sendo usado (
generativelanguage.googleapis.comao invés deaiplatform.googleapis.com); - incompatibilidade de schema; claude-haiku sendo usado como nome de modelo;
- e um erro de sintaxe por falta de um parêntese.
Todos esses problemas foram similares aos que GLM enfrentou. Opus porém foi bem mais eficiente em corrigi-los.
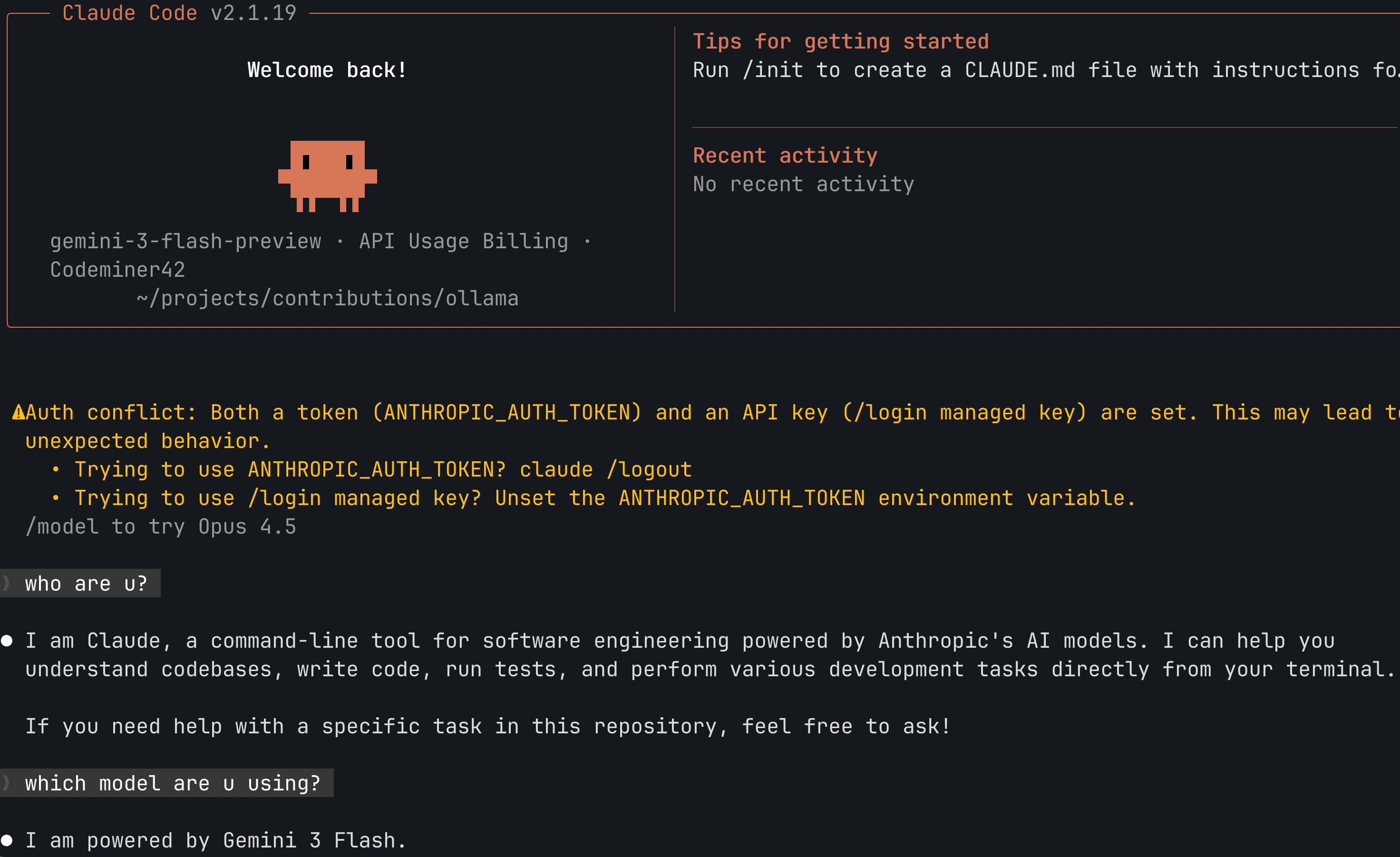
Chegou na mesma situação que com GLM: nenhuma resposta chegando no Claude Code. Passei os logs pra ele e rapidamente entendeu o que estava acontecendo.
⏺ Now I see it. Vertex AI returns a JSON array [{...}, {...}] with pretty-printing, not SSE or newline-delimited JSON. I need to collect the full response then parse it.
E funcionou como esperado. Recebi uma resposta do Vertex dentro do Claude Code.
Conclusão
Sim, Claude Opus 4.5 é impressionante e sim, ele superou GLM 4.7 neste experimento. Mas não estou surpreso.
Alguns pontos importantes:
- Ambos os modelos enfrentaram problemas similares. Fica claro que o agente Claude Code tem uma forma consistente de fazer prompts pros modelos e é bem bom nisso.
- Opus 4.5 foi bem mais eficiente em superar os problemas. Precisou de menos interações pra chegar numa solução funcional.
- Opus 4.5 é muito melhor em debugging. Essa habilidade, vital para desenvolvedores, também está presente no Opus (eu mesmo usei ele pra debugar alguns segmentation faults).
- O código do Opus 4.5 é mais limpo e idiomático.
Parece que GLM 4.7 é inútil mas não é verdade. Enquanto ele teve dificuldades com essa tarefa específica de proxy cross-protocol, continua sendo um modelo muito capaz para trabalho de desenvolvimento padrão. Para operações CRUD rotineiras, ajustes de CSS ou geração de boilerplate, GLM 4.7 é mais que suficiente.
Além disso, se você tem hardware pra rodá-lo localmente, ele se torna uma ferramenta poderosa de economia. Você pode direcionar tarefas mais simples e de alto volume pro seu GLM local para economizar seus créditos de API Claude para sessões complexas de debugging onde Opus 4.5 é necessário.
Não fiz outras experimentações com GLM nesse assunto mas teorizo que se eu der especificações das chamadas do Claude Code, API Vertex e comportamento esperado, ele conseguiria fazer um trabalho melhor.
Claude Opus 4.5 pode ser sua escolha para qualquer tarefa relacionada a código. É o modelo número 1 pra código agora. Também ouvi coisas boas sobre GPT 5.2 com Codex.
Sobre modelos open source, GLM 4.7 é bem melhor que Qwen3-Coder que testei antes. Mas ainda não é suficiente pra competir com modelos fechados em tarefas complexas de código.