Quanto de RAM é suficiente? Rodando LLMs no MacBook com Ollama
Recentemente, iniciei meus estudos sobre LLMs (e IAs no geral) de maneira séria. Fazer um estudo sério sobre isso exige ler papers e papers sobre os modelos, arquiteturas, técnicas de treinamento etc. e também praticar com os modelos. Prompt Engineering e Sampling, por exemplo, são dois tópicos que exigem prática em modelos variados.
Usar LLMs através de APIs na nuvem é uma ótima maneira de começar, mas tem suas desvantagens. A latência e o custo podem ser um problema, especialmente quando você está experimentando e iterando rapidamente. Além disso, a privacidade dos dados é uma preocupação crescente. Ter um modelo localmente permite que você mantenha seus dados privados e seguros.
Até aqui, tenho utilizado o Ollama, uma ferramenta que fornece interface simples para baixar e executar modelos, além de fornecer uma API para interagir com eles.
Assim como muitos, antes de começar, sempre imaginei que para usar Ollama e rodar modelos localmente precisaria de muito poder computacional. Eu não sou o cara do hardware, tive apenas três computadores próprios na vida, sendo o mais potente deles um MacBook Air de 2015 com 8GB de RAM, processador Intel i3 e um SSD de 256GB.
Minha máquina atual é um MacBook Pro com chip M3, GPU de 18 cores, 18GB de RAM e SSD de 1TB, fornecida pela empresa onde trabalho. Conversei com pessoas que entendem bem mais que eu sobre o assunto e me garantiram que é possível montar PCs com hardware até mais poderoso que o meu, por um preço bem mais acessível.
Instalando Ollama
Existem algumas formas de se instalar o Ollama no Mac. Desde baixando direto no site até via Docker ou Homebrew. Eu segui uma outra abordagem, buildando a partir do código fonte, que está disponível no GitHub do Ollama.
As dependências são: Go e um compilador C/C++ (Xcode Command Line Tools no macOS). Com isso, basta clonar o repositório e já executar os comandos do ollama.
$ git clone git@github.com:ollama/ollama.git
$ cd ollama
$ go run . serve
O comando acima já inicia o servidor do Ollama. Agora, no mesmo diretório, em outro terminal, podemos executar comandos do Ollama, como por exemplo:
$ go run . run qwen3
A partir daí, é só utilizar o modelo como quiser. Você pode passar prompts diretamente na linha de comando, ou interagir com o modelo via API HTTP.
Para simplificar o uso, eu resolvi gerar o binário do Ollama com o comando:
$ go build .
Esse comando gera um arquivo chamado ollama no diretório atual. Assim você pode executar os comandos mostrados anteriormente, mas sem precisar do go run . na frente. Além disso, pode adicionar o binário ao PATH do sistema, para facilitar ainda mais o uso.
Tamanho dos Modelos
Para o meu histórico, considero a máquina que uso muito boa. Mas claro, ela possui suas limitações. Cada modelo tem suas variações de tamanho e requisitos de hardware. Isso pode ser observado na página de cada modelo no site do Ollama.
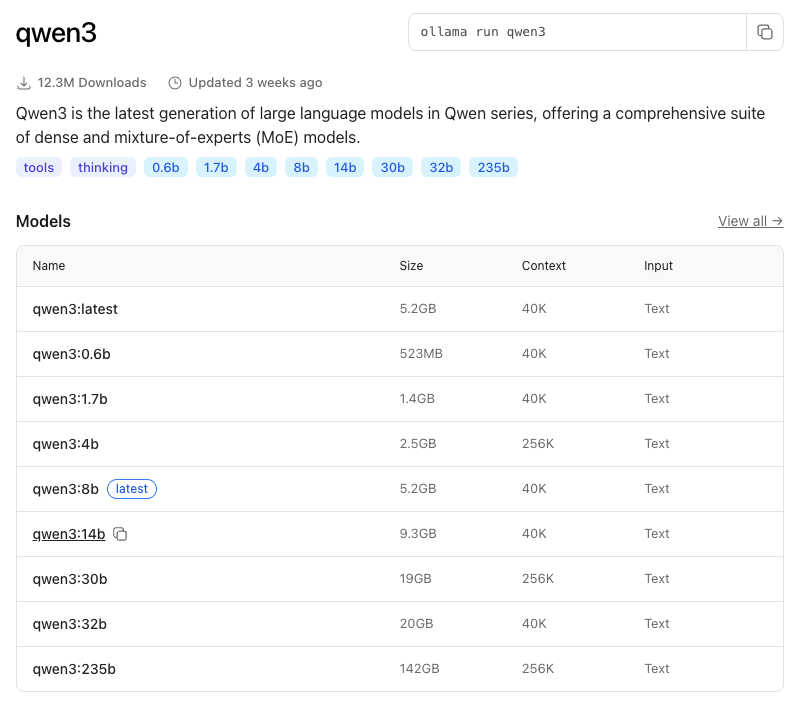
Cada linha informa sobre a quantidade de parâmetros, tamanho do contexto e (aproximadamente a) RAM necessária para rodar o modelo.
Mais parâmetros não significa melhor desempenho
Modelos maiores (com mais parâmetros) têm maior capacidade de aprendizado e podem capturar padrões mais complexos nos dados. No entanto, é importante observar que mais parâmetros não necessariamente significam melhor desempenho. Modelos menores podem ser otimizados para tarefas específicas e podem oferecer desempenho comparável ou até superior em certos cenários.
Contexto, Embeddings e Quantização
O comando ./ollama show [model] exibe, entre outras informações, tamanho de contexto, embeddings e quantização do modelo.
$ ./ollama show qwen3
Model
architecture qwen3
parameters 8.2B
context length 40960
embedding length 4096
quantization Q4_K_M
- Context Length: Refere-se ao número máximo de tokens que o modelo pode considerar ao gerar uma resposta. Um contexto maior permite que o modelo leve em conta mais informações anteriores na conversa, o que pode melhorar a coerência e relevância das respostas.
- Embedding Length: Refere-se ao tamanho dos vetores de embedding usados pelo modelo. Embeddings são representações numéricas de palavras ou frases que capturam seu significado semântico. Um comprimento maior de embedding pode permitir que o modelo capture nuances mais finas no significado das palavras.
- Quantization: Refere-se à técnica de reduzir a precisão dos pesos do modelo para economizar memória e acelerar a inferência. Diferentes esquemas de quantização (como Q4_K_M) têm diferentes trade-offs entre precisão e eficiência. É devido à quantização que modelos grandes possam ser executados em hardware com recursos limitados.
Considerações Finais
Tenho utilizado modelos diferentes há algumas semanas através do Ollama e tem sido uma experiência muito positiva. O modelo Qwen3, em especial, tem se mostrado bastante competente para uma variedade de tarefas.
Como meu computador é limitado em termos de hardware, tenho limitado o uso a modelos que ocupem até 10GB de RAM, evitando erros que já tive como o mostrado abaixo:

Recentemente, comecei experimentos com o modelo multimodal Qwen3-VL de oito bilhões de parâmetros, que suporta entrada de imagens. Foi bem para algumas tarefas simples como pedir descrição de imagens, mas quando tentei, por exemplo, converter uma tabela presente na imagem para um markdown, o modelo ficou num loop eterno gerando asteriscos.
Fiz o mesmo pedido ao mesmo modelo em chat.qwen.ai, que é a versão hospedada na nuvem, e o resultado foi 100% satisfatório, com a tabela corretamente convertida para markdown.
A partir de hoje, vou testar modelos maiores direto no Ollama Cloud, que é a versão paga do Ollama que roda na nuvem. Assim, consigo comparar os resultados entre o modelo local e o modelo na nuvem.