De zero código a thumbnails gerados por IA em 4 dias
O blog da Codeminer42 não tinha personalidade visual.
Cada autor gerava a thumbnail do seu post do jeito que dava - a maioria usando ChatGPT ou Nano Banana, cada um com seu estilo. O resultado era um blog onde cada capa parecia de um site diferente. Não existia um padrão, uma identidade.
Eu decidi resolver isso. A ideia era criar uma linguagem visual consistente pro blog - algo que uma pessoa olhasse e pensasse “isso é da Codeminer”. Mas antes de automatizar qualquer coisa, eu precisava descobrir qual era esse estilo.
Esse post é a história do Kanario - um gerador de thumbnails que vai do draft ao .png em 60 segundos. Mas não é um tutorial de “como usar a ferramenta”. É o relato da construção: o que funcionou, o que quebrou, e as dezenas de iterações até chegar num resultado que presta.
Procurando o estilo
Comecei testando modelos de imagem. Queria algo que pudesse pegar o mascote do blog (o mineiro, de capacete e mochila) e colocá-lo dentro de cenas diferentes. Testei Flux, z-image e Qwen.
Flux e z-image geravam imagens bonitas mas não conseguiam pegar o mascote e colocá-lo dentro de uma cena. O Qwen Image Edit fez algo diferente: ele recebe uma imagem de referência e desenha uma cena ao redor, integrando o personagem. Eu mandava o mascote e ele voltava dentro de um cenário, interagindo com os objetos. Dos três, foi o único que pegava o mascote e construía uma cena de verdade ao redor dele.
O estilo isométrico 3D, tipo render Pixar, apareceu por acidente. Testei vários estilos de prompt - flat, cartoon, realista - e o isométrico foi o que funcionou melhor com o Qwen. As cenas ficavam limpas, os objetos legíveis, e o mascote não se deformava.
O Colab
Por algumas semanas, fiquei gerando imagens manualmente no Google Colab com a biblioteca diffusers:
from diffusers import QwenImageEditPlusPipeline
pipeline = QwenImageEditPlusPipeline.from_pretrained(
"Qwen/Qwen-Image-Edit-2509", torch_dtype=torch.bfloat16
)
inputs = {
"image": [Image.open("mascot.png").convert("RGB")],
"prompt": "Isometric 3D scene, Pixar-style render, pure white background...",
"true_cfg_scale": 4.0,
"negative_prompt": " ",
"num_inference_steps": 40,
}
with torch.inference_mode():
output = pipeline(**inputs)
O processo era lento. Escrevia o prompt na mão, rodava, esperava, olhava o resultado, ajustava, rodava de novo. Mas foi desse ciclo manual que saiu o estilo: background branco, sombras mínimas, ângulo isométrico fixo, mascote ocupando 1/3 do canvas. Cada decisão veio de dezenas de tentativas.
Com o estilo definido e validado, ficou claro que o processo podia ser automatizado. O que mudava entre um post e outro era a metáfora visual - os objetos, a ação do mascote, as cores. O estilo era fixo.
A ideia
Se o estilo é fixo e o que muda é a metáfora, então o problema de gerar uma thumbnail se reduz a:
- Entender do que o post fala
- Criar uma metáfora visual (a “cena”)
- Descrever essa cena num prompt
- Gerar a imagem
Os passos 1 e 2 são trabalho de LLM. O passo 3 é prompt engineering. O passo 4 é o Qwen, que eu já conhecia bem. Dá pra automatizar tudo.
O protótipo: WordPress + Claude + Qwen
O primeiro commit foi um script TypeScript direto: buscar o draft via REST API do WordPress, mandar o conteúdo pro Claude gerar um prompt de cena, e mandar esse prompt pro Qwen gerar a imagem.
Parecia simples. E a versão inicial gerou imagens. Só que eram ruins.
O mascote ficava deformado. As cenas não tinham relação com o post. Os prompts eram genéricos demais. Mas a coisa funcionava de ponta a ponta - do WordPress ao .png. Eu tinha um ponto de partida.
Rodando o Qwen na nuvem
No Colab eu rodava o Qwen numa A100 High RAM do Google. Minha máquina não aguenta um modelo de 65GB. Pra ferramenta funcionar como CLI, eu precisava do Qwen acessível via API.
O primeiro plano foi subir um FastAPI com o pipeline do diffusers no Google Cloud - um Compute Engine com A100 80GB. Eu já tinha o server.py pronto, o Dockerfile, o script de deploy. Mas quando fui criar a VM, esbarrei em quota: a Google exige aprovação pra usar A100, e eu não tinha.
Procurei alternativas e achei o RunPod. Sem burocracia de quota, A100 sob demanda. Comecei a montar um template custom com o mesmo Dockerfile, mas aí descobri que o RunPod Hub já tinha um endpoint público pro Qwen Image Edit. Sem precisar de imagem Docker, sem gerenciar pod. Mando o request, recebo o resultado. Era exatamente o que eu queria pra primeira versão: a coisa mais simples possível.
O endpoint do RunPod Hub é assíncrono: você submete o job, recebe um ID, e faz polling até o resultado voltar. Isso abriu a porta pra paralelizar - mandar 4 jobs de uma vez e esperar todos voltarem. A geração de 4 imagens caiu de “uma de cada vez, 2 minutos no total” pra “4 em paralelo, 30 segundos”.
Aprendendo a falar com o Qwen
Os primeiros prompts que o Claude gerava pro Qwen eram do tipo “a miner character in a tech environment with servers”. Vago. O Qwen gerava qualquer coisa - às vezes bonita, quase sempre desconectada do post.
Aí comecei a estudar o que funciona com o Qwen Image Edit e fui ajustando o system prompt do Claude passo a passo.
Primeiro, depth layering. O Qwen responde bem a descrições com profundidade de câmera: “no foreground, o mascote segura X; no background, Y”. Adicionei isso como regra.
Depois, mascotes. No começo era sempre o mesmo. Adicionei a opção de escolha - miner (capacete, mochila, trabalho braçal) ou hat (óculos, chapéu, vibe intelectual). O LLM escolhe qual combina mais com o tema do post. A gente também definiu uma paleta de backgrounds com mood: cream (acolhedor), sky (tecnologia), slate (dramático), plum (criativo).
Mas o que mais fez diferença foi trocar “cenas” por “metáforas visuais”. O prompt original pedia “cenas” pro post. O LLM interpretava isso como “ilustre o conteúdo literalmente”. Um post sobre background jobs virava um cara parado olhando pra um servidor. Quando mudei pra “visual metaphors - a diorama that captures the post’s essence”, debugging virou “mascote abrindo um servidor rachado com um pé de cabra”. Bem melhor.
A troca pra Gemini
O primeiro protótipo usava Claude pra gerar os prompts. Rapidamente fiz uns testes comparando com Gemini (na época o 2.0 Flash, depois troquei pro Gemini 3 Pro preview). O Gemini gerou prompts melhores, mais rápido e mais barato. Virou o padrão. O Claude ficou como flag opcional (--model claude).
O ponto aqui é que os dois modelos compartilham o mesmo system prompt e o mesmo schema de output. Trocar um pelo outro é mudar uma linha. O investimento real foi no system prompt - e esse é agnóstico de modelo.
Widescreen e o mascote gigante
No começo, as imagens saíam quadradas. O Qwen gera na mesma proporção da imagem de entrada. Então adicionei um passo de padding: o mascote é posicionado num canvas 16:9 antes de ir pro Qwen. A saída já vem no formato de thumbnail.
Mas aí veio o primeiro tombo visual sério: o mascote ocupava metade do canvas. As cenas ficavam claustrofóbicas - o personagem dominava tudo e os objetos ficavam apertados ao redor dele.
Reduzi o mascote pra 1/3 da largura do canvas. Isso deu espaço pro diorama respirar. A cena virou um “palco” com o mascote como um dos elementos, não o protagonista absoluto.
O comando pick: fechando o ciclo
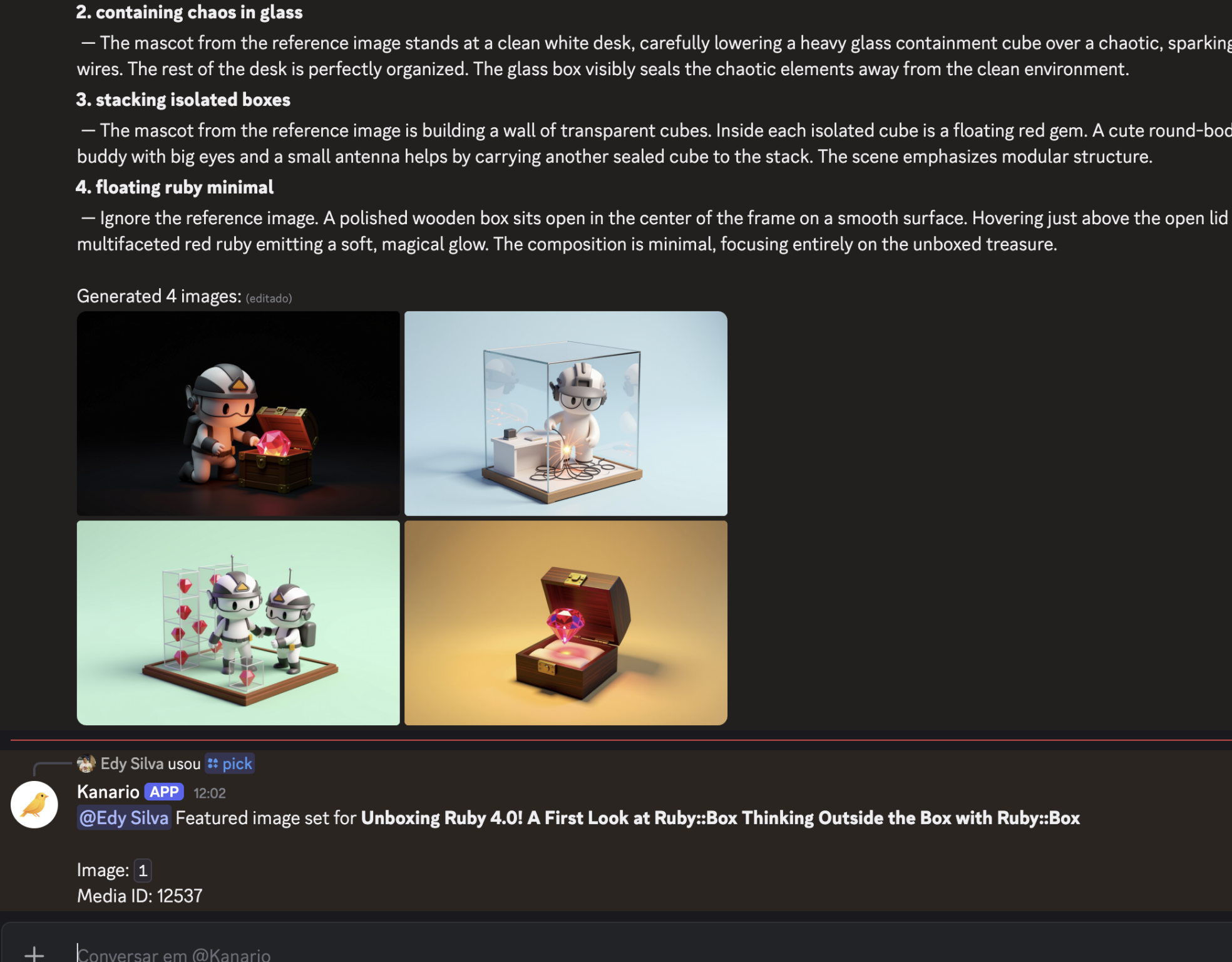
Gerar thumbnails é metade do trabalho. Depois você precisa escolher uma, subir pro WordPress e setar como featured image. Isso era manual. Então adicionei o comando pick:
./kanario pick 12232 2
Ele pega a imagem prompt-2.png do post 12232, faz upload via REST API do WordPress, e seta como featured image. O ciclo inteiro - do draft à capa publicada - virou dois comandos.
O mascote opcional (e o LLM que fazia “balanceamento de cota”)
Nem toda cena precisa de personagem. Um post sobre “a crise do software” pode funcionar melhor como um diorama de objetos: uma pilha de servidores rachados, uma ampulheta quebrada. Adicionei none como opção de mascote - quando o LLM escolhe none, o Kanario manda um canvas branco pro Qwen e a descrição começa com “Ignore the reference image.”
Mas aí apareceu um comportamento estranho: o LLM sempre gerava exatamente 3 cenas com mascote e 1 sem. Post sobre Docker? 3+1. Post sobre Margaret Hamilton? 3+1. Post sobre ActiveJob? 3+1. Parecia estar fazendo “balanceamento de cota” ao invés de decidir por cena.
A fix foi uma frase no system prompt: “decide independently per scene, don’t aim for a mix.” Depois disso, um post sobre Margaret Hamilton gera 4 cenas com mascote (faz sentido - é sobre uma pessoa). Um post sobre arquitetura pode gerar 4 sem. O LLM parou de contar.
A sumarização: quando o conteúdo afoga o título
Um post pode ter 30 mil caracteres. Jogar tudo isso no prompt de geração de cena desperdiçava tokens e, pior, diluía o que importa. O LLM lia o conteúdo inteiro e gerava cenas sobre detalhes do parágrafo 15 - ao invés de captar a metáfora do título.
A fix teve duas partes. Primeiro, sumarizar antes: o Kanario passa o conteúdo por um modelo rápido (Gemini Flash) que extrai os pontos-chave em ~1.500 caracteres. O prompt generator recebe o resumo, não o conteúdo bruto. Segundo, priorizar o título. Reformatei a mensagem do usuário pra deixar claro: “Here’s the blog post title (this is the primary input - derive the visual metaphor from this)”. O conteúdo virou “supporting detail only”.
Depois dessas mudanças, um post chamado “How AI Wiped Out 80% of Tailwind’s Revenue” parou de gerar cenas de “pessoa usando computador” e começou a gerar tornados destruindo lojas.
Os tombos do prompt tuning
Se eu tivesse que resumir o projeto numa frase seria: 90% do trabalho é prompt tuning. Eu não escrevi uma linha de código do Kanario. Tudo foi feito pareando com o Claude Code - eu descrevia o que queria, ele implementava, eu avaliava o resultado. Agentic engineering. O código saiu rápido. O prompt tuning, não. Algumas lições que doeram:
“Robot” vira o mascote
O system prompt original dizia pra usar “a tiny robot” como personagem secundário. O problema: o Qwen recebe o mascote como imagem de referência. Quando o prompt diz “robot”, o Qwen interpreta que o “robot” É o mascote da referência - e renderiza dois mascotes idênticos.
A solução foi trocar “robot” por “a cute round-bodied bot buddy with big eyes and a small antenna” - descritivo o suficiente pra o Qwen não confundir com a referência.
Bot buddy em todo lugar
Mesmo depois de resolver o “robot”, o LLM continuava enfiando um bot buddy em cenas onde não fazia sentido. Um post sobre Ruby::Box aparecia com um robozinho colando caixas. A seção sobre personagens secundários era lida como um convite: “quando possível, adicione alguém.”
A fix: reformular pra “only add a second character when the post is about interaction between two entities”. A maioria dos posts não precisa de um segundo personagem.
O hint que ninguém seguia
O Kanario aceita --hint pra guiar a metáfora: ./kanario 12232 --hint "tornado destruindo uma loja". O system prompt dizia “follow it literally”. O LLM tratava como sugestão - uma cena seguia o hint, as outras três faziam o que queriam.
A fix: mudar pra “hard constraint that every scene must satisfy”. Agora as 4 cenas refletem o hint.
O smoke test que salvou o projeto
Testes unitários garantem que o código funciona. Mas pra saber se os prompts são bons, você precisa gerar imagens de verdade e olhar. Criei um smoke test que gera thumbnails pra 5 posts fixos (técnico, biográfico, opinião, negócios, tutorial) e abre as pastas pra revisão manual.
Cada mudança no system prompt passava pelo smoke test: rodar, abrir as 20 imagens, avaliar visualmente, anotar o que melhorou e o que piorou. Não tem como automatizar “essa imagem ficou boa?” - é julgamento humano. Mas ter um processo repetível pra esse julgamento fez toda a diferença.
O bot do Discord
O CLI funciona, mas ninguém da equipe ia abrir um terminal pra gerar thumbnail. Então construí um bot do Discord.
O primeiro desafio foi o timeout: o Discord exige resposta em 3 segundos, e a geração leva 60+. A solução é usar “deferred responses” - o bot responde imediatamente com um loading state e edita a mensagem quando termina.
Mas durante os 60 segundos de geração, o usuário ficava olhando pro nada. O Discord mostra “thinking…” no deferred, mas assim que você edita a mensagem, o indicador some. Adicionei progress updates em tempo real - cada etapa do pipeline edita a mensagem com um relógio que avança: 🕐 → 🕑 → 🕒…
O segundo desafio foi credenciais. O blog da Codeminer é multi-autor. Cada pessoa precisa autenticar com seu próprio Application Password do WordPress. O bot tem /register (em DM, pra não expor senha no canal), que valida as credenciais contra a API do WordPress e salva num SQLite criptografado com AES-256-GCM.
Depois adicionei /pick (escolher e setar como featured image) e /improve (pegar uma imagem gerada e pedir alterações com um novo prompt). O ciclo inteiro funciona sem sair do Discord.
O deploy
O bot roda no Cloud Run. O deploy é um script:
GCP_PROJECT_ID=edy-ai-playground ./deploy/deploy.sh
Build da imagem Docker, push pro Artifact Registry, deploy. 2 minutos. O SQLite das credenciais fica num bucket GCS montado via FUSE - persiste entre cold starts sem precisar de banco externo.
O que eu aprendi
Prompt tuning se parece mais com treinar um modelo do que com escrever software. Você muda uma frase no system prompt, gera imagens pra 5 posts, olha, ajusta, gera de novo. Não é “escreva o prompt certo e pronto”. É um loop iterativo com feedback visual.
E o que você não diz importa tanto quanto o que você diz. Metade dos problemas eram coisas que o LLM inventava porque o prompt não proibia. O bot buddy aparecia porque o prompt encorajava, não porque a cena pedia. O hint era ignorado porque o prompt dizia “follow” ao invés de “must satisfy”.
Desde o começo eu sabia que gerar o mascote do zero toda vez seria furada. Por isso foquei em modelos que trabalham com imagem de referência. O Qwen ganhou de Flux e z-image justamente nisso - pegava o mascote e construía uma cena ao redor dele sem deformar, sem inventar outro personagem.
Ferramentas internas precisam de UX. O CLI funcionava, mas a adoção só veio com o Discord bot. Cada atrito que eu removia (progress updates, credenciais por usuário, /improve pra iterar) aumentava o uso. O Pragmatic Programmer fala de “make it easy to do the right thing” - pra ferramentas internas isso vale em dobro.
O resultado
Eu gastava 30 minutos por thumbnail e evitava o processo. Agora rodo um comando, espero 60 segundos, e tenho 4 opções com metáforas visuais que realmente têm a ver com o post. O blog da Codeminer tem uma identidade visual consistente, e cada post tem uma capa que captura a essência do conteúdo.
É isso!