O Event Loop do Node não é o que te ensinaram
Era 2025 e eu queria ver o event loop funcionando com meus próprios olhos. Não num diagrama, não num artigo - no código.
Eu já era colaborador do Node na época. Mas tinha uma diferença entre saber explicar o event loop e ter visto ele rodar. Eu queria a segunda coisa.
Daí eu fiz o que qualquer pessoa razoável faria: compilei o Node do zero, compilei o libuv do zero, enfiei console.log e std::cout em tudo que é canto do código fonte e fiquei olhando o que acontecia.
O que todo mundo te ensina (e o que tá errado)
Se você pesquisar “Node.js event loop” vai encontrar mil diagramas bonitos. A maioria te mostra uma caixa com uma fila de eventos, uma call stack, e setas girando. Parece simples. Parece limpo.
É mentira.
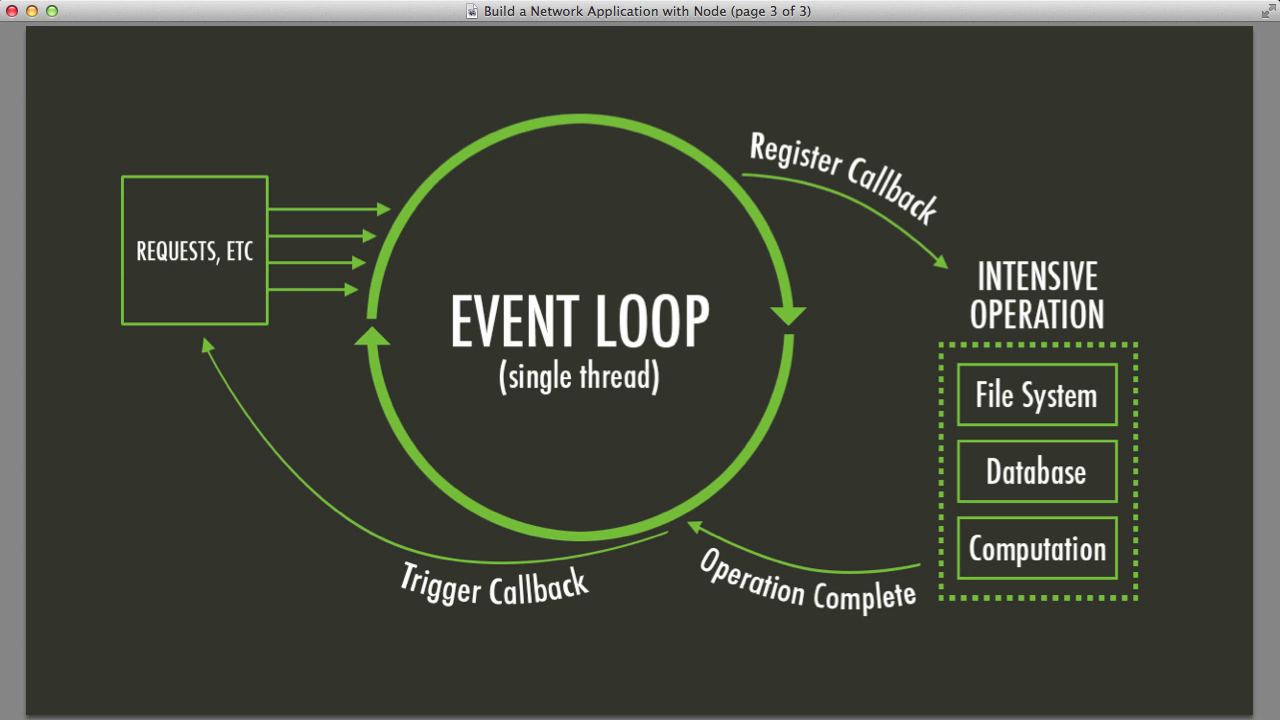
Não é uma fila simples. Não é uma pilha girando. E muitas operações de rede nem passam por threads separadas - rodam direto no kernel do sistema operacional.
Quem me abriu os olhos pra isso foi o Bert Belder - um dos criadores do libuv - numa palestra de 2017:
Morning Keynote: Everything You Need to Know About Node.js Event Loop - Bert Belder, IBM
Tem 9 anos. Ele começa corrigindo exatamente esses equívocos que a gente repete sem questionar. Eu já tinha assistido dezenas de vídeos sobre event loop e nenhum chegou perto desse.
A estrutura real do event loop
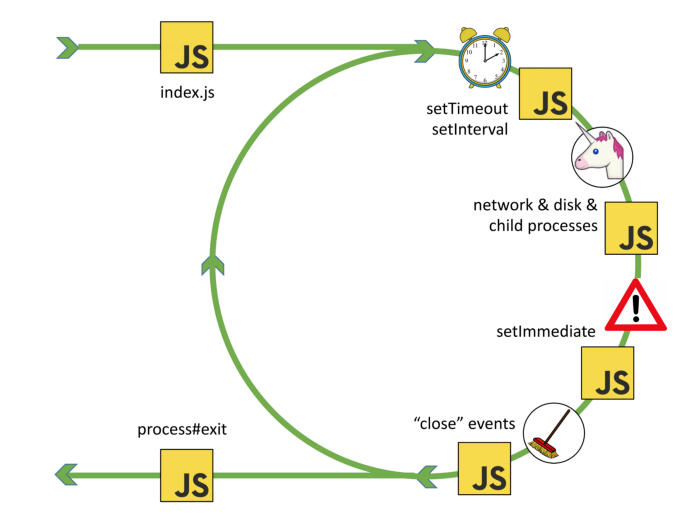
O que o Belder explica - e que eu confirmei enfiando prints no código - é que o event loop do Node tem fases bem definidas. Não é uma fila genérica. Cada volta do loop passa por:
- Timers - verifica se algum
setTimeoutousetIntervalexpirou - I/O (o Belder chama de “Unicorn”) - a fase principal, onde o libuv lida com rede, disco e processos filhos
- setImmediate - executa os callbacks agendados com
setImmediate - Close handlers - limpeza de sockets fechados
E aqui vem o que pra mim é o maior gotcha do event loop: entre cada fase, código JavaScript é executado. O Node drena a fila de microtasks do V8 (Promises resolvidas) e também os callbacks de process.nextTick. Ou seja, entre Timers e I/O, entre I/O e setImmediate, entre setImmediate e Close handlers - sempre tem esse passo intermediário onde JS roda.
A maioria dos diagramas que você encontra por aí não mostra isso. Eles te dão as 4 fases bonitinhas e pronto. Mas na prática, o libuv não sabe nada sobre microtasks - isso é conceito do V8. O libuv cuida das fases do loop, e o Node é quem costura as duas coisas: depois que cada fase do libuv termina, o Node pede pro V8 drenar as microtasks pendentes e drena o nextTick também. É nessa costura que mora a confusão.
NOTA: O
thread pooldo libuv (geralmente 4 threads) só entra em ação pra operações que o sistema operacional não consegue fazer de forma assíncrona nativamente - como manipulação de arquivos e pesquisas DNS. Operações de rede usam mecanismos do kernel comoepoll(Linux) ekqueue(macOS) diretamente.
Prints em C++ e JavaScript
O jeito “certo” de fazer isso seria com lldb (no macOS) - breakpoints, inspecionar a stack, seguir o fluxo sem modificar o código. Hoje em dia com IA fica ainda mais fácil: você pode pedir pro Claude usar lldb pra debugar, analisar stack traces, navegar pelo código fonte. Eu mesmo usei IA assim pra resolver segmentation faults enquanto trabalhava em implementações no Node.
Mas pra esse experimento eu escolhi console.log e std::cout. A técnica mais primitiva que existe. Qualquer pessoa sabe colocar um print - e pra entender o fluxo do event loop era mais que suficiente.
Em src/api/embed_helpers.cc, no coração do loop:
do {
if (env->is_stopping()) break;
std::cout << "node called uv_run() in SpinEventLoopInternal" << std::endl;
uv_run(env->event_loop(), UV_RUN_DEFAULT);
std::cout << "Gotta drain tasks" << std::endl;
platform->DrainTasks(isolate);
more = uv_loop_alive(env->event_loop());
// ...
} while (more && !env->is_stopping());
Em src/api/callback.cc, onde os ticks são processados:
if (!tick_info->has_tick_scheduled()) {
std::cout << "No tick scheduled, draining microtask queue" << std::endl;
context->GetMicrotaskQueue()->PerformCheckpoint(isolate);
}
// ...
std::cout << "Tick callback being called from C++" << std::endl;
No lado JavaScript, em lib/internal/process/task_queues.js:
function processTicksAndRejections() {
let tock;
// all the next tick callbacks are processed here
do {
while ((tock = queue.shift()) !== null) {
// ...
callback();
qLength--;
}
runMicrotasks();
} while (!queue.isEmpty() || processPromiseRejections());
}
Daí eu criei scripts de teste pra observar a ordem de execução. Que nem esse aqui:
const { styleText } = require('node:util');
function printMessage(message) {
const text = styleText(['cyanBright', 'bold'], `\t\t\t\t${message}\n`)
process.stdout.write(text);
}
new Promise((resolve) => {
printMessage('(0) Promise constructor was called')
resolve('(1) Promise resolved');
}).then(printMessage);
setTimeout(() => {
printMessage('(2) settimeout was called');
process.nextTick(() => {
printMessage('(2.1) nextTick inside setTimeout was called');
});
}, 100);
setImmediate(() => {
printMessage('(3) setImmediate was called');
process.nextTick(() => {
printMessage('(3.1) nextTick inside setImmediate was called');
});
});
process.nextTick(() => {
printMessage('(4) nextTick was called');
});
printMessage('(5) This log comes first');
Executando com meu Node compilado cheio de prints eu conseguia ver o que tava acontecendo por baixo. Cada std::cout no C++ casava com o que eu via no JavaScript. A ficha caiu.
nextTick: o nome mais mentiroso do Node
Agora a parte que me incomodou.
O process.nextTick não executa no “próximo tick”. Ele executa no tick atual. O nome é uma mentira descarada.
Olha o que acontece quando você aninha nextTick:
process.nextTick(() => {
printMessage('(1) nextTick was called');
process.nextTick(() => {
printMessage('(2) inner nextTick was called');
process.nextTick(() => {
printMessage('(4) inner-inner nextTick was called');
});
});
});
setImmediate(() => {
printMessage('(3) setImmediate was called');
});
O setImmediate ali no (3)? Ele não executa enquanto tiver nextTick pendente. Porque cada nextTick novo que é agendado dentro de outro nextTick entra na mesma fila que tá sendo drenada naquele momento. É que nem ir ao supermercado e a cada item que você coloca no carrinho aparecer mais dois na lista - você nunca sai do corredor.
Isso é por design, claro. O nextTick drena completamente antes de qualquer fase do event loop continuar. Mas chamar isso de “next tick”? É como chamar o freio de mão de “acelerador reserva”.
Eu “corrigi” o Node
Já que eu tava com o código aberto na minha frente, pensei: por que não?
Criei o process.nesteTick. Faz a mesma coisa que o nextTick, mas com um nome honesto.
“Neste” em português significa “in this” - ou seja, nesteTick = “neste tick” = “neste ciclo atual”. Que é exatamente o que ele faz.
Em lib/internal/process/task_queues.js:
function nesteTick(callback) {
nextTick(callback);
}
E registrei em lib/internal/bootstrap/node.js:
const { nextTick, runNextTicks, nesteTick } = setupTaskQueue();
process.nextTick = nextTick;
process.nesteTick = nesteTick;
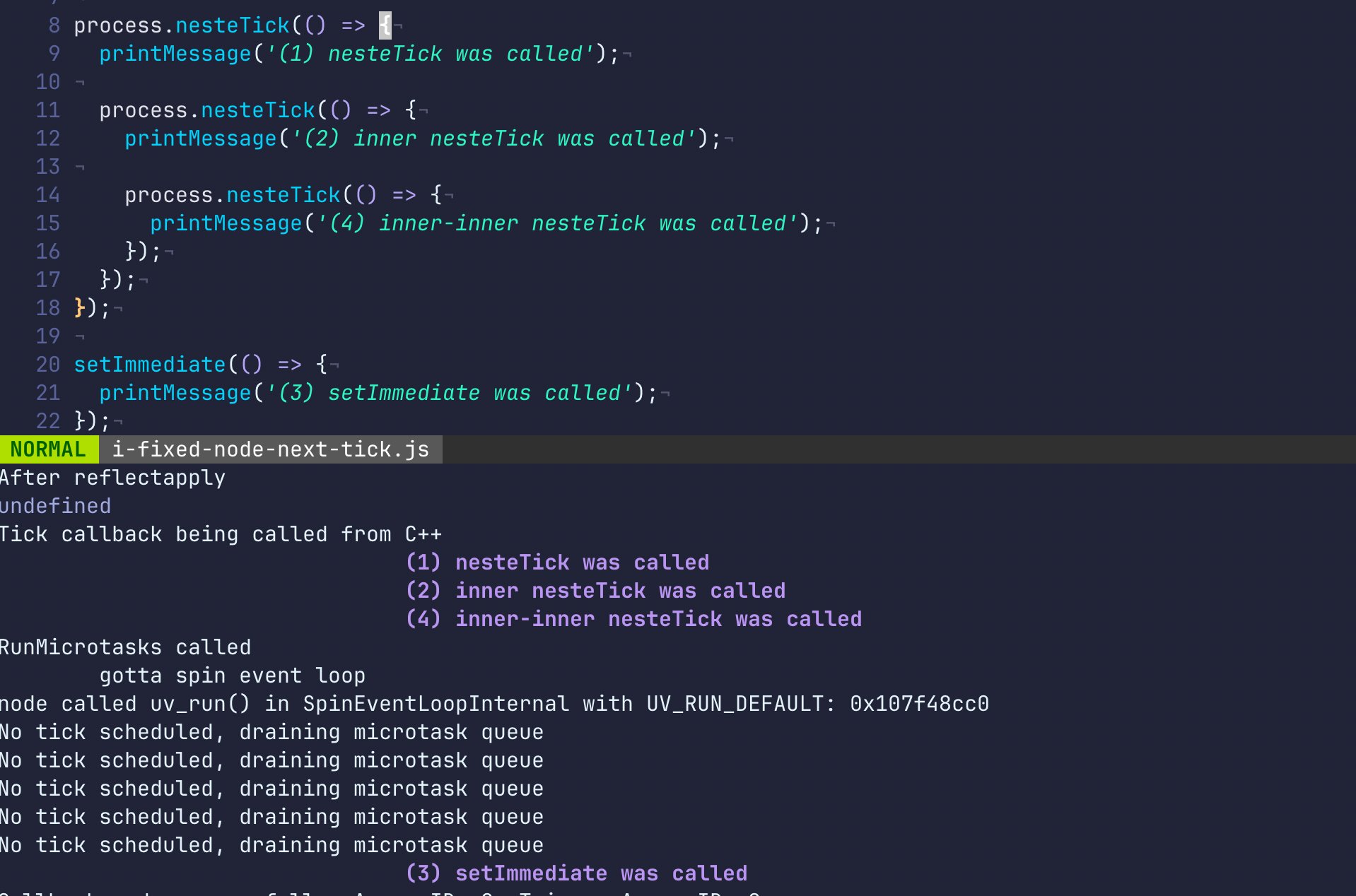
Daí o script de demonstração:
process.nesteTick(() => {
printMessage('(1) nesteTick was called');
process.nesteTick(() => {
printMessage('(2) inner nesteTick was called');
process.nesteTick(() => {
printMessage('(4) inner-inner nesteTick was called');
});
});
});
setImmediate(() => {
printMessage('(3) setImmediate was called');
});
Funciona igualzinho. Mas agora o nome não te engana.
O que ficou depois
Eu poderia ter lido mais 10 artigos sobre event loop. Poderia ter assistido mais 20 vídeos. Mas nada substituiu abrir o código, compilar, e ver as coisas acontecendo.
Colocar uns prints no código fonte e observar o fluxo? Você para de repetir frases decoradas e começa a saber.
Se você trabalha com Node todo dia e nunca olhou o código fonte - nem que seja com grep pra achar onde as coisas acontecem - tenta. O código do Node é mais legível do que você imagina.
Recursos
- Morning Keynote: Everything You Need to Know About Node.js Event Loop - Bert Belder
- Meu branch com os experimentos - o código com todos os prints e o
nesteTickPor hoje é só. Abraços.